
AI & Machine Learning in 2026: A Deep Dive for Developers
Artificial Intelligence is no longer a research curiosity locked inside university labs. It is the engine powering the products millions of people use every single day — from the search bar you typed into this morning to the recommendation that kept you on Netflix for three extra hours last night.
Most tutorials miss the point: understanding AI/ML deeply is what separates developers who use AI tools from developers who build them. This guide is for the second group.
We go from first principles all the way to production-grade systems. No hand-waving.
1. What Actually Is Machine Learning?
Traditional programming is deterministic: you write rules, the computer follows them. Machine learning flips this. You give the system data and desired outcomes, and it figures out the rules itself.
"Machine learning is the science of getting computers to act without being explicitly programmed." — Andrew Ng
There are three core paradigms:
| Paradigm | What it learns from | Classic example |
|---|---|---|
| Supervised Learning | Labeled input-output pairs | Email spam detection |
| Unsupervised Learning | Raw unlabeled data | Customer segmentation |
| Reinforcement Learning | Rewards and penalties | Game-playing agents, robotics |
2. The Neural Network: Nature's Blueprint, Reimagined
A neural network is a mathematical function that maps inputs to outputs through layers of interconnected nodes. Each connection has a weight — a number that gets tuned during training.
Here is the simplest possible neural network in PyTorch:
textimport torch import torch.nn as nn class SimpleNet(nn.Module): def __init__(self): super().__init__() self.layers = nn.Sequential( nn.Linear(784, 256), # Input: 28x28 pixel image flattened nn.ReLU(), # Activation: introduces non-linearity nn.Dropout(0.2), # Regularization: prevents overfitting nn.Linear(256, 128), nn.ReLU(), nn.Linear(128, 10), # Output: 10 classes (digits 0-9) ) def forward(self, x): return self.layers(x) model = SimpleNet() print(f"Parameters: {sum(p.numel() for p in model.parameters()):,}") # Parameters: 234,634
The magic happens during backpropagation — the algorithm that computes how much each weight contributed to the error and adjusts them accordingly. This is just the chain rule from calculus, applied recursively.
The Activation Function: Why It Matters
Without activation functions, stacking layers is mathematically equivalent to a single linear transformation — useless for complex patterns. Activations introduce non-linearity.
textimport torch import torch.nn.functional as F x = torch.linspace(-5, 5, 200) # Common activations and where they're used relu = torch.relu(x) # ResNet, CNNs gelu = F.gelu(x) # GPT, BERT transformers silu = F.silu(x) # LLaMA, Mistral tanh = torch.tanh(x) # RNNs, LSTMs # GELU and SiLU are smooth approximations of ReLU # They perform better in transformer architectures
3. The Transformer: The Architecture That Changed Everything
In 2017, a paper titled "Attention Is All You Need" dropped and quietly rewrote the rules of AI. The Transformer architecture replaced recurrent networks with a mechanism called self-attention.
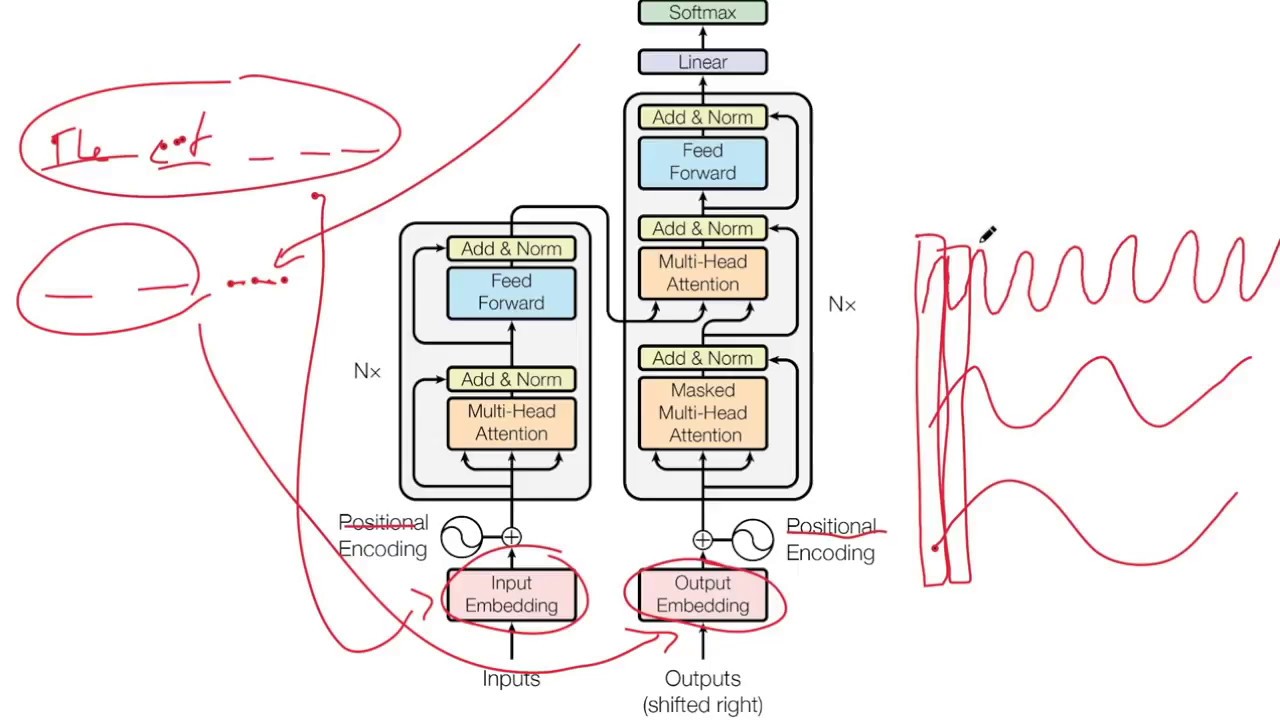
Self-Attention in Plain English
Imagine reading: "The animal didn't cross the street because it was too tired."
What does "it" refer to? The animal, not the street. Humans resolve this instantly using context. Self-attention gives neural networks the same ability — every token can look at every other token and decide how much to attend to it.
textimport torch import torch.nn.functional as F import math def scaled_dot_product_attention(Q, K, V, mask=None): """ Q: Query [batch, heads, seq_len, d_k] K: Key [batch, heads, seq_len, d_k] V: Value [batch, heads, seq_len, d_k] """ d_k = Q.size(-1) # Step 1: Compute raw attention scores scores = torch.matmul(Q, K.transpose(-2, -1)) / math.sqrt(d_k) # Step 2: Apply causal mask (for autoregressive models) if mask is not None: scores = scores.masked_fill(mask == 0, float('-inf')) # Step 3: Softmax -> attention weights (sum to 1) weights = F.softmax(scores, dim=-1) # Step 4: Weighted sum of values return torch.matmul(weights, V), weights
Multi-Head Attention
A single attention head might track grammatical relationships. Another might track semantic similarity. Running them in parallel and concatenating gives the model a richer representation.
textimport torch.nn as nn class MultiHeadAttention(nn.Module): def __init__(self, d_model=512, num_heads=8): super().__init__() assert d_model % num_heads == 0 self.d_k = d_model // num_heads self.num_heads = num_heads self.W_q = nn.Linear(d_model, d_model) self.W_k = nn.Linear(d_model, d_model) self.W_v = nn.Linear(d_model, d_model) self.W_o = nn.Linear(d_model, d_model) def split_heads(self, x, batch_size): return x.view(batch_size, -1, self.num_heads, self.d_k).transpose(1, 2) def forward(self, x): B = x.size(0) Q = self.split_heads(self.W_q(x), B) K = self.split_heads(self.W_k(x), B) V = self.split_heads(self.W_v(x), B) out, _ = scaled_dot_product_attention(Q, K, V) out = out.transpose(1, 2).contiguous().view(B, -1, self.num_heads * self.d_k) return self.W_o(out)
4. Large Language Models: How They Actually Work
An LLM is a transformer trained on a massive corpus of text with one objective: predict the next token. That is it. No magic. Just next-token prediction at incomprehensible scale.
| Model | Parameters | Training Tokens | Context Window |
|---|---|---|---|
| GPT-2 (2019) | 1.5B | 40B | 1,024 |
| GPT-3 (2020) | 175B | 300B | 4,096 |
| LLaMA 3.1 (2024) | 405B | 15T | 128,000 |
| Gemini 1.5 Pro (2024) | ~1T est. | Unknown | 1,000,000 |
Tokenization: The Hidden Layer
Before text enters a model, it is broken into tokens — subword units. The vocabulary is typically 32,000–128,000 tokens.
textfrom transformers import AutoTokenizer tokenizer = AutoTokenizer.from_pretrained("meta-llama/Meta-Llama-3-8B") text = "Transformers are revolutionizing AI development in 2026." tokens = tokenizer.encode(text) decoded = [tokenizer.decode([t]) for t in tokens] print(f"Token count: {len(tokens)}") print(f"Tokens: {decoded}") # ['Trans', 'form', 'ers', ' are', ' revolution', 'izing', ' AI', ...] # Notice: "Transformers" splits into 3 tokens, "2026" splits into 2
Running Inference
textfrom transformers import AutoModelForCausalLM, AutoTokenizer import torch model_name = "meta-llama/Meta-Llama-3-8B-Instruct" tokenizer = AutoTokenizer.from_pretrained(model_name) model = AutoModelForCausalLM.from_pretrained( model_name, torch_dtype=torch.bfloat16, # Half precision: ~50% less VRAM device_map="auto", # Distribute across available GPUs ) messages = [ {"role": "system", "content": "You are a helpful AI assistant."}, {"role": "user", "content": "Explain backpropagation in one paragraph."}, ] input_ids = tokenizer.apply_chat_template( messages, add_generation_prompt=True, return_tensors="pt" ).to(model.device) with torch.no_grad(): output = model.generate( input_ids, max_new_tokens=256, temperature=0.7, # Controls randomness (0 = deterministic) top_p=0.9, # Nucleus sampling do_sample=True, ) response = tokenizer.decode(output[0][input_ids.shape[-1]:], skip_special_tokens=True) print(response)
5. Fine-Tuning: Making Models Yours
Pre-trained models are general. Fine-tuning makes them specialists. There are three main approaches.
Full Fine-Tuning
Update all parameters. Most powerful, most expensive. Requires the same hardware as pre-training.
LoRA: Low-Rank Adaptation
The dominant technique. Instead of updating the full weight matrix W, you learn two small matrices A and B such that the update equals A times B. This reduces trainable parameters by 99%+ while retaining most performance.
textfrom peft import LoraConfig, get_peft_model, TaskType from transformers import AutoModelForCausalLM import torch base_model = AutoModelForCausalLM.from_pretrained( "meta-llama/Meta-Llama-3-8B", torch_dtype=torch.bfloat16, device_map="auto", ) lora_config = LoraConfig( task_type=TaskType.CAUSAL_LM, r=16, # Rank: lower = fewer params, higher = more expressive lora_alpha=32, # Scaling factor (usually 2x rank) lora_dropout=0.05, target_modules=[ "q_proj", "k_proj", "v_proj", "o_proj", "gate_proj", "up_proj", "down_proj", ], bias="none", ) model = get_peft_model(base_model, lora_config) model.print_trainable_parameters() # trainable params: 41,943,040 || all params: 8,072,204,288 || trainable%: 0.52
RLHF and DPO
RLHF (Reinforcement Learning from Human Feedback) is how ChatGPT learned to be helpful and harmless. In 2026, DPO (Direct Preference Optimization) has largely replaced the PPO step — it is simpler, more stable, and achieves comparable alignment results.
6. RAG: Giving Models Long-Term Memory
LLMs have a knowledge cutoff. They hallucinate facts. They cannot access your private data. Retrieval-Augmented Generation solves all three.
textUser Query ↓ Embed query → dense vector ↓ Search vector database for similar chunks ↓ Inject retrieved context into prompt ↓ LLM generates grounded, cited response
textfrom langchain_community.vectorstores import Chroma from langchain_openai import OpenAIEmbeddings, ChatOpenAI from langchain.text_splitter import RecursiveCharacterTextSplitter from langchain_community.document_loaders import PyPDFLoader from langchain.chains import RetrievalQA # 1. Load and chunk documents loader = PyPDFLoader("your_document.pdf") documents = loader.load() splitter = RecursiveCharacterTextSplitter( chunk_size=1000, chunk_overlap=200, # Overlap prevents context loss at boundaries ) chunks = splitter.split_documents(documents) # 2. Embed and store in vector DB embeddings = OpenAIEmbeddings(model="text-embedding-3-large") vectorstore = Chroma.from_documents(chunks, embeddings) # 3. Build retrieval chain llm = ChatOpenAI(model="gpt-4o", temperature=0) qa_chain = RetrievalQA.from_chain_type( llm=llm, chain_type="stuff", retriever=vectorstore.as_retriever(search_kwargs={"k": 5}), return_source_documents=True, ) result = qa_chain.invoke({"query": "What are the key findings?"}) print(result["result"])
7. AI Agents: From Chatbots to Autonomous Systems
The frontier of AI in 2026 is agentic systems — models that can plan, use tools, and execute multi-step tasks autonomously.
The core loop: Observe → Think → Act → Observe → Think → Act...
textfrom langchain.agents import AgentExecutor, create_tool_calling_agent from langchain_openai import ChatOpenAI from langchain_core.tools import tool from langchain_core.prompts import ChatPromptTemplate @tool def search_web(query: str) -> str: """Search the web for current information.""" # Integrate with Tavily, Serper, or Brave Search API return f"Search results for: {query}" @tool def run_python(code: str) -> str: """Execute Python code in a sandbox and return output.""" import io, contextlib output = io.StringIO() with contextlib.redirect_stdout(output): exec(code, {}) return output.getvalue() tools = [search_web, run_python] llm = ChatOpenAI(model="gpt-4o", temperature=0) prompt = ChatPromptTemplate.from_messages([ ("system", "You are a helpful AI assistant with tools. Think step by step."), ("human", "{input}"), ("placeholder", "{agent_scratchpad}"), ]) agent = create_tool_calling_agent(llm, tools, prompt) executor = AgentExecutor(agent=agent, tools=tools, verbose=True, max_iterations=10) result = executor.invoke({ "input": "Search for the latest PyTorch version, then write Python that prints it." })
Multi-Agent Systems with LangGraph
Single agents hit limits on complex tasks. LangGraph lets you build networks of specialized agents that collaborate.
textfrom langgraph.graph import StateGraph, END from typing import TypedDict, Annotated import operator class AgentState(TypedDict): messages: Annotated[list, operator.add] next: str def researcher(state: AgentState): # Searches and gathers information return {"messages": ["Research complete"], "next": "writer"} def writer(state: AgentState): # Synthesizes research into output return {"messages": ["Draft complete"], "next": "reviewer"} def reviewer(state: AgentState): approved = True # Based on quality check return {"messages": ["Review done"], "next": END if approved else "writer"} workflow = StateGraph(AgentState) workflow.add_node("researcher", researcher) workflow.add_node("writer", writer) workflow.add_node("reviewer", reviewer) workflow.set_entry_point("researcher") workflow.add_edge("researcher", "writer") workflow.add_edge("writer", "reviewer") workflow.add_conditional_edges("reviewer", lambda s: s["next"]) app = workflow.compile()
8. Evaluating AI Systems
Building a model is 20% of the work. Knowing whether it is actually good is the other 80%.
| Metric | Use Case | Notes |
|---|---|---|
| Accuracy | Classification | Misleading on imbalanced datasets |
| F1 Score | Imbalanced classes | Harmonic mean of precision and recall |
| BLEU | Text generation | n-gram overlap with reference |
| ROUGE | Summarization | Recall-oriented n-gram overlap |
| Perplexity | Language modeling | Lower = better next-token prediction |
| MMLU | LLM benchmarking | 57-subject multi-task accuracy |
textfrom openai import OpenAI import json client = OpenAI() def llm_judge(question: str, answer: str, reference: str) -> dict: """Use GPT-4o as an evaluator — the LLM-as-judge pattern.""" response = client.chat.completions.create( model="gpt-4o", messages=[{ "role": "user", "content": f"""Rate this answer 1-10 for accuracy and helpfulness. Question: {question} Reference: {reference} Answer: {answer} Respond with JSON only: {{"score": <1-10>, "reasoning": "<brief>"}}""" }], response_format={"type": "json_object"}, ) return json.loads(response.choices[0].message.content)
9. Deploying ML Models to Production
A model that lives in a Jupyter notebook helps no one.
textfrom fastapi import FastAPI, HTTPException from pydantic import BaseModel from transformers import pipeline app = FastAPI(title="ML Inference API") # Load once at startup — never per request classifier = pipeline( "text-classification", model="distilbert-base-uncased-finetuned-sst-2-english", device=0, # GPU; use -1 for CPU ) class Request(BaseModel): text: str class Response(BaseModel): label: str confidence: float @app.post("/predict", response_model=Response) async def predict(req: Request): if not req.text.strip(): raise HTTPException(status_code=400, detail="Text cannot be empty") result = classifier(req.text)[0] return Response(label=result["label"], confidence=round(result["score"], 4)) @app.get("/health") async def health(): return {"status": "healthy"}
textFROM python:3.11-slim WORKDIR /app COPY requirements.txt . RUN pip install --no-cache-dir -r requirements.txt COPY . . # Pre-download model weights at build time RUN python -c "from transformers import pipeline; pipeline('text-classification', model='distilbert-base-uncased-finetuned-sst-2-english')" EXPOSE 8000 CMD ["uvicorn", "main:app", "--host", "0.0.0.0", "--port", "8000", "--workers", "4"]
10. The AI/ML Learning Roadmap
| Phase | Timeline | Focus |
|---|---|---|
| Foundation | Months 1-3 | Linear algebra, calculus, Python, NumPy, scikit-learn |
| Core ML | Months 4-6 | Deep learning, PyTorch, CNNs, RNNs, Transformers |
| LLM Engineering | Months 7-9 | Prompt engineering, RAG, fine-tuning with LoRA |
| Production | Months 10-12 | FastAPI serving, vLLM, MLflow, monitoring |
11. What Is Next: The Frontier
Test-Time Compute — Models like OpenAI o3 and DeepSeek R1 spend more compute at inference time thinking through problems step by step. This trades latency for accuracy on hard reasoning tasks.
Mixture of Experts (MoE) — Instead of activating all parameters for every token, MoE models route each token to a subset of expert sub-networks. Mixtral 8x7B achieves GPT-3.5 quality at a fraction of the inference cost.
On-Device AI — Apple Intelligence, Qualcomm NPUs, and models like Phi-3-mini (3.8B params) are bringing capable AI to phones and laptops without cloud dependency.
Multimodal Agents — The next wave of models does not just reason — it acts. Controlling computers, writing and running code, browsing the web, filling forms. The line between AI assistant and AI employee is blurring fast.
"The models we have today are the worst models we will ever use. Everything from here is upward." — Sam Altman
Wrapping Up
We covered a lot of ground — from the math of backpropagation to deploying models in Docker containers. The key insight is that AI/ML is not magic. It is engineering, applied at scale, with a healthy dose of empiricism.
The developers who will shape the next decade are not the ones who wait for AI to be finished. They are the ones building with it right now, learning from failures, and iterating fast.
Start with one concept from this post. Build something small. Break it. Fix it. That is the loop.

Vighnesh Salunkhe
"Passionate about building scalable web applications and exploring the intersection of AI and human creativity."
Join the Conversation
Share your thoughts or ask a question